
Dữ liệu Python thô (mã nguồn thô) thường chứa lỗi, thiếu sót hoặc không đồng nhất, khiến kết quả phân tích bị sai lệch. Do đó chúng ta cần làm sạch dữ liệu Python trước khi phân tích. Vậy làm sạch dữ liệu Python là gì và quy trình làm sạch như thế nào? Cùng tìm hiểu trong bài viết này của Code Dream nhé!
Làm sạch dữ liệu là gì? Làm sạch dữ liệu Python là gì?
Làm sạch dữ liệu (Data Cleaning) là quá trình phát hiện, sửa chữa hoặc loại bỏ các dữ liệu không chính xác, bị thiếu, trùng lặp hoặc không nhất quán trong tập dữ liệu. Mục tiêu của bước này là tạo ra một bộ dữ liệu “sạch”, đáng tin cậy để phục vụ cho phân tích và mô hình hóa.
Làm sạch dữ liệu Python là việc sử dụng ngôn ngữ Python cùng các thư viện phổ biến như Pandas, NumPy để thực hiện các thao tác xử lý dữ liệu. Nhờ cú pháp đơn giản và hệ sinh thái mạnh mẽ, Python trở thành công cụ hàng đầu trong lĩnh vực phân tích và khoa học dữ liệu hiện nay.
6 bước làm sạch dữ liệu Python chi tiết, dễ hiểu
Trong thực tế, dữ liệu thu thập được hiếm khi “sạch” ngay từ đầu. Vì vậy, khi làm sạch dữ liệu Python, bạn nên thực hiện theo từng bước rõ ràng để tránh bỏ sót lỗi quan trọng.
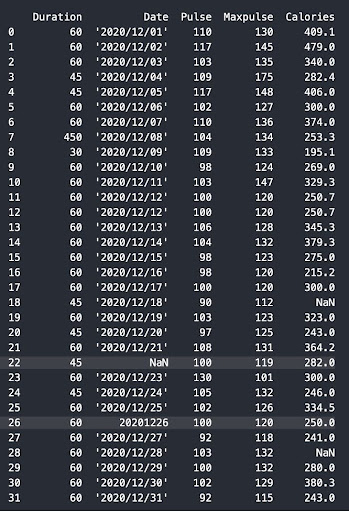
Bước 1: Khảo sát nhanh dữ liệu (shape, type, missing)
Mục tiêu của bước này là biết dataset có bao nhiêu dòng, bao nhiêu cột, kiểu dữ liệu từng cột và cột nào đang thiếu dữ liệu nhiều.
Ở đây bạn cần kiểm tra:
- Số dòng / số cột
- Kiểu dữ liệu (object, int, float, datetime)
- Tỷ lệ giá trị thiếu theo từng cột
Ví dụ:
import pandas as pd
data = {
“order_id”: [101, 102, 103, 103, 104],
“customer”: [“An”, “Bình”, “Dung”, “Dung”, None],
“price”: [“1,200,000đ”, “800000”, None, “800000”, “1.500.000đ”],
“quantity”: [1, 2, -1, -1, 1],
“order_date”: [“2024-01-01”, “01/02/2024”, “2024-01-03”, “2024-01-03”, “2024/01/05”]
}
df = pd.DataFrame(data)
Trong ví dụ trên thì:
- Dataset có 5 dòng – 5 cột
- price và customer có giá trị thiếu
- price đang là object (chuỗi)
- order_date chưa phải kiểu datetime
- Có khả năng trùng đơn hàng order id = 103
Bước 2 : Phát hiện và xử lý giá trị thiếu (missing values)
Ở bước này, bạn cần sử dụng các hàm như .isnull() để kiểm tra:
- Cột nào thiếu nhiều
- Thiếu có mang tính ngẫu nhiên hay không
- Thiếu có ảnh hưởng đến phân tích hay không. Nếu cột thiếu >50% → cân nhắc loại bỏ
Sau khi đánh giá, ta sẽ quyết định giữ nguyên, thay thế (imputation) bằng hàm .fillna() hoặc loại bỏ bằng hàm .dropna().
Ví dụ:
“customer”: [“An”, “Bình”, “Dung”, “Dung”, None],
Ở đây ta có thể thay thế “None” bằng “unknown” để dữ liệu trở nên đúng.
Bước 3 : Chuẩn hóa kiểu dữ liệu (data types)
Nếu không chuẩn hóa kiểu dữ liệu, Python sẽ:
- Không tính được tổng, trung bình
- Gây lỗi khi dùng thuật toán hoặc biểu đồ
Vì vậy ở bước này bạn cần đảm bảo mỗi cột có đúng kiểu dữ liệu để xử lý và tính toán. Để làm được điều đó chúng ta cần kiểm tra:
- Số bị lưu dưới dạng chuỗi (object): Cần chuyển về int hoặc float.
- Ngày tháng chưa phải datetime: Cần dùng pd.to_datetime() để có thể trích xuất thứ, ngày, tháng, năm.
- Cột phân loại bị nhầm kiểu: Chuyển sang kiểu category để tiết kiệm bộ nhớ.
Ví dụ:
“price”: [“1,200,000đ”, “800000”, “800000”, “1.500.000đ”],
Ở đây ta cần chuyển “1,200,000đ” -> 1200000
Bước 4 : Xử lý dữ liệu sai hoặc không hợp lệ
Trong bước này bạn cần kiểm tra:
- Giá trị âm không hợp lý (tuổi, giá tiền)
- Giá trị vượt ngưỡng thực tế
- Ký tự lạ, dữ liệu nhập sai
Mục tiêu ở đây là loại bỏ hoặc sửa các giá trị vô lý so với thực tế.
Ví dụ:
“quantity”: [1, 2, -1, -1, 1],
Trong ví dụ trên quantity = -1 là không hợp lệ trong thực tế. Chúng ta có thể thay bằng 1 để tránh làm sai kết quả, hoặc có thể thay bằng NaN nếu muốn xử lý nghiêm ngặt hơn.
Bước 5 : Chuẩn hóa giá trị (format, text, category)
Mục tiêu của bước này là đưa dữ liệu về một chuẩn thống nhất để dễ phân tích.
Ở đây bạn cần kiểm tra:
- Chữ hoa – chữ thường
- Khoảng trắng dư
- Giá trị cùng nghĩa nhưng khác cách viết
Bước 6: Phát hiện và loại bỏ dữ liệu trùng lặp
Bước này nhằm đảm bảo mỗi bản ghi chỉ xuất hiện một lần duy nhất.
Bạn cần kiểm tra:
- Toàn bộ dòng
- Toàn bộ khóa chính (email, id, mã đơn)
Ví dụ:
“order_id”: [101, 102, 103, 103, 104],
Trong ví dụ, order_id = 103 bị trùng. Nếu không loại bỏ, kết quả sẽ bị tính gấp đôi.
Bước 7 : Kiểm tra lại và xác nhận dữ liệu đã “sạch”
Bước cuối cùng này giúp đảm bảo dữ liệu không chỉ “sạch” mà còn chính xác và đáng tin cậy khi sử dụng.
Bạn cần kiểm tra:
- Không còn missing
- Kiểu dữ liệu đúng
- Phân bố dữ liệu hợp lý
Học lập trình Python tại Code Dream
Để làm sạch dữ liệu Python, người học cần nền tảng Python vững chắc và tư duy xử lý dữ liệu đúng hướng. Vậy bạn đã biết học Python ở đâu uy tín chưa? Nếu chưa, hãy đến với Code Dream.
Tại Code Dream, chương trình lập trình Python cho trẻ em được thiết kế bài bản từ cơ bản đến nâng cao, giúp các em làm quen với cách thao tác dữ liệu, sử dụng thư viện Pandas, NumPy và từng bước áp dụng vào các bài toán thực tế phù hợp với độ tuổi.
Code Dream tập trung rèn tư duy logic, khả năng phân tích và thực hành thường xuyên, giúp học viên không chỉ biết viết code mà còn hiểu cách xử lý dữ liệu chuyên nghiệp. Đây là nền tảng quan trọng để tiếp tục học phân tích dữ liệu, AI hay thuật toán nâng cao.

Code Dream sẵn sàng đồng hành cùng bạn trên hành trình chinh phục Python, xây dựng nền tảng vững chắc để phát triển lâu dài trong lĩnh vực dữ liệu và công nghệ.
Trên đây là toàn bộ kiến thức tổng quan về làm sạch dữ liệu Python, từ khái niệm đến các bước thực hiện chi tiết. Hy vọng thông qua bài viết này, bạn đã nắm vững quy trình, từ đó dễ dàng tiếp cận các lĩnh vực phân tích dữ liệu và trí tuệ nhân tạo một cách hiệu quả và bền vững.








