
Đồ thị (Graph) Phần 2: Tổ chức dữ liệu
Ở bài viết Đồ thị (Graph) Phần 1: Các khái niệm cơ bản, chúng ta đã tìm hiểu về các khái niệm, thuật ngữ cơ bản trong đồ thị, tại bài viết này chúng ta cùng tìm hiểu thêm về cách biểu diễn đồ thị trong lập trình nhé!
1. Đặt vấn đề
Trong lý thuyết đồ thị, việc tổ chức, lưu trữ dữ liệu cho từng bài toán, thuật toán rất quan trọng, nó quyết định kích thước dữ liệu bài toán, thời gian thực tế của bài toán.
Dữ liệu đồ thị thu thập trong thực tế được lưu trữ bằng danh sách các quan hệ kết nối giữa đỉnh và cạnh. Có 3 cách tổ chức dữ liệu thường hay dùng để lưu trữ các quan hệ giữa chúng, thuận tiện trong việc truy cập và xử lý:
- Danh sách cạnh
- Ma trận kề
- Danh sách kề
Bài toán
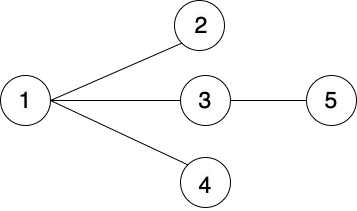
Xây dựng cấu trúc dữ liệu để mô tả đồ thị sau:
Đồ thị có \(n = 5\) đỉnh và có \(m = 4\) cặp cạnh.
2. Tổ chức dữ liệu bằng danh sách cạnh
Danh sách cạnh trong lý thuyết đồ thị được lưu trữ vào mảng một chiều, mỗi phần tử của mảng sẽ thể hiện thông tin của 2 đỉnh kề nhau.
Trong đồ thị trên có 4 cặp cạnh là: \( (1, 2), (1,3), (1, 4), (3, 5) \)
Vì mỗi phần tử của mảng phải thể hiện cả hai thông tin, nên ta có thể dùng kiểu \( pair< int,int> \), hoặc \(struct\) cho mỗi phần tử của mảng hay thậm chí là sử dụng hai mảng một chiều để lưu trữ cũng đáp ứng được yêu cầu.
Sample Input
1 2 1 3 1 4 3 5
Code mẫu sử dụng pair C++
#include <bits/stdc++.h> using namespace std; int n, m;//khai báo số đỉnh và cạnh pair<int, int> edge[200005];//khai báo mảng lưu cạnh int main() { cin >> n >> m; for (int i = 1; i <= m; i++) cin >> edge[i].first >> edge[i].second; return 0; }
3. Tổ chức dữ liệu bằng ma trận kề
Giả sử chúng ta có một đơn đồ thị vô hướng không trọng số, có \(n\) đỉnh. Chúng ta coi như các đỉnh được đánh số từ \(1\) đến \(n\).
Tổ chức dữ liệu theo kiểu ma trận kề trong lý thuyết đồ thị bằng cách xây dựng ma trận vuông \(a[i][j]\) cấp \(n\). Với:
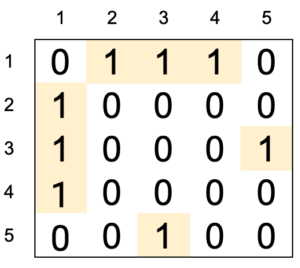
- \(a[i][j] = 1\) khi đồ thị có cạnh nối từ đỉnh \(i\) đến đỉnh \(j\).
- \(a[i][j] = 0\) khi đồ thị không có cạnh nối từ đỉnh \(i\) đến đỉnh \(j\).
Ma trận kề cho đồ thị trên được mô tả như sau
Nếu đề bài cho Input là ma trận kề thì ta chỉ việc đọc dữ liệu như bình thường và lưu vào mảng hai chiều, còn nếu đề bài cho Input là danh sách cạnh như phần trước thì ta sẽ thực hiện như sau:
- Ban đầu gán tất cả các phần tử của ma trận kề bằng \(0\) (coi như chưa có cạnh nối)
- Với mỗi cạnh \((u, v)\) được đọc từ Input, ta thực hiện gán \(a[u][v]=1\) và \(a[v][u]=1\)
Code mẫu tạo ma trận kề C++
#include <bits/stdc++.h> using namespace std; int n, m;//khai báo số đỉnh và cạnh int a[1005][1005]; //khai báo ma trận kề int main() { cin >> n >> m; for (int i = 1; i <= m; i++){ int u, v; cin >> u >> v; a[u][v] = 1; a[v][u] = 1; } return 0; }
4. Tổ chức dữ liệu bằng danh sách kề
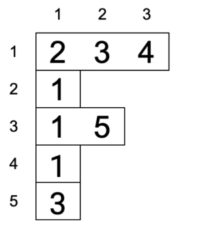
Tổ chức dữ liệu bằng danh sách kề bằng cách xây dựng một mảng 2 chiều \(adj\) có \(n\) hàng và số cột không cố định kích thước, với ý nghĩa: Hàng \(u\) chứa các đỉnh kề với đỉnh thứ \(u\). Có thể dùng một mảng n phần tử, với mỗi phần tử của mảng là một vector để lưu.
Dữ liệu danh sách kề của đồ thị trên được mô tả như sau
Nếu đề bài cho Input là danh sách cạnh như phần trước thì với mỗi cạnh \((u, v)\) được đọc từ Input ta sẽ thực hiện như sau:
- Thêm phần tử \(v\) vào hàng thứ \(u\): \(a[u].push\_back(v)\)
- Thêm phần tử \(u\) vào hàng thứ \(v\): \(a[v].push\_back(u)\)
Code mẫu tạo danh sách kề C++
#include <bits/stdc++.h> using namespace std; int n, m;//khai báo số đỉnh và cạnh vector<int> adj[100005]; //khai báo danh sách kề int main() { cin >> n >> m; for (int i = 1; i <= m; i++){ int u, v; cin >> u >> v; adj[u].push_back(v); adj[v].push_back(u); } return 0; }
5. Tổ chức dữ liệu cho đồ thị có trọng số và có hướng
Bên trên chúng ta nói về đồ thị không trọng số, và vô hướng. Vậy nếu đồ thị có trọng số, hay có hướng thì sao?
Tổ chức dữ liệu cho đồ thị sau:
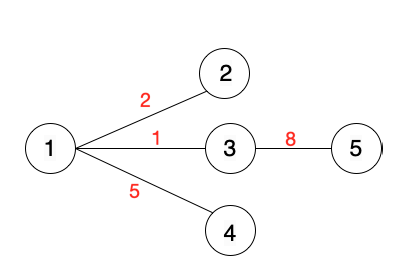
Danh sách cạnh
Nếu đồ thi có trọng số thì chúng ta khai báo \( pair< pair< int, int>, int> \) để lưu được 3 thông tin, hai thông tin về đỉnh và một thông tin trọng số. Kết quả là ta sẽ có 1 bộ 3 giá trị thể hiện 1 cạnh \((x,y,c)\)
Nếu đồ thì có hướng và dữ liệu đề bài nói rõ cạnh đi từ \(u\) đến \(v\) thì bạn không cần làm gì thêm, khi duyệt các đỉnh trên đồ thị không đi ngược lại cạnh \((y,x)\) là được.
Ma trận kề
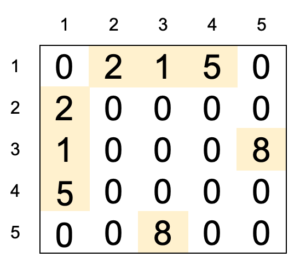
Nếu đồ thi có trọng số thì chúng ta thay \(a[u][v]=1\) và \(a[v][u]=1\) đó thành \(a[u][v]=a[v][u]=c\) (Với \(c\) chính là trọng số của cạnh đó). Điều này các bạn sẽ thấy rõ khi tiếp cận các thuật toán căn bản như Floyd, Dijkstra, Prim….
Nếu đồ thì có hướng, và dữ liệu đề bài nói rõ cạnh đi từ \(u\) đến \(v\) thì bạn chỉ gán \(a[u][v]=1\) và ko gán chiều ngược lại là được.
Hình ảnh mô tả ma trận kề có trọng số
Danh sách kề
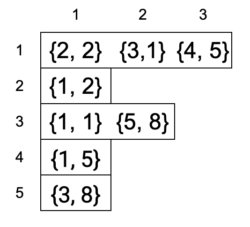
Nếu đồ thi có trọng số thì tại mỗi phần tử của vector chúng ta thay vì lưu mỗi tên đỉnh ta sử dụng \(pair\) để lưu 1 cặp (tên đỉnh, trọng số)
- Khai báo danh sách kề: \(vector< pair< int, int> > adj[100005]; \)
- Thêm phần tử \(v\) với trọng số \(c\) vào hàng \(u\): \( adj[u].push\_back( \{ v,c \})\)
- Thêm phần tử \(u\) với trọng số \(c\) vào hàng \(v\): \( adj[v].push\_back( \{ u,c \})\)
Nếu đồ thì có hướng, và dữ liệu đề bài nói rõ cạnh đi từ \(u\) đến \(v\) thì bạn chỉ gán \( adj[u].push\_back( \{ v,c \}) \) và ko gán chiều ngược lại là được.
Hình ảnh mô tả danh sách kề có trọng số
6. So sánh, đánh giá
Danh sách cạnh
Cách tổ chức này khá dễ viết, chúng thường được dùng trong thuật toán căn bản như tìm cây khung kruskal.
Nếu chi phí duyệt và không gian lưu trữ của ma trận kề là \(n^2\) thì phương án tổ chức dữ liệu bằng danh sách cạnh chỉ mất \(2*m\). Giảm được rất nhiều về chi phí và thời gian duyệt nếu đồ thị thưa (đồ thị có ít cạnh)
Nhưng khi ta muốn duyệt tất cả cạnh kề của một đỉnh nào đó, lúc này chẳng có cách nào ngoài việc duyệt hết danh sách cạnh đó và lọc ra để xử lí, đặc biệt là khi đồ thị dày (đồ thị có nhiều cạnh) thì thời gian duyệt sẽ tăng lên rất nhiều.
Ma trận kề
Dễ dàng nhận thấy vì sử dụng mảng 2 chiều nên kích thước dữ liệu chúng ta tốn \(n^2\) và độ phức tạp của dữ liệu này cũng là \(O(n^2)\).
Nhưng ma trận kề trong lý thuyết đồ thị cũng có ưu điểm là khi nhìn vào dữ liệu được tổ chức bằng ma trận kề, thì dễ dàng nhận biết được 2 đỉnh nào kề với nhau trong \(O(1)\), chúng ta dễ cài đặt, và biết được bậc của từng đỉnh nếu đó là đồ thị đơn.
Danh sách kề
Ưu điểm của danh sách kề là chi phí duyệt và lưu trữ khá tối ưu. Đặc biệt là danh sách kề trong mảng.
- Chi phí bộ nhớ \(O(2∗m)\)
- Chi phí duyệt toàn đồ thị \(O(m+n)\)
Đối với từng bài toán cụ thể, tùy vào dữ liệu bài toán cho, các bạn hãy lựa chọn cách tổ chức dữ liệu phù hợp nhất, không nhất thiết lúc nào cũng tổ chức danh sách kề.
7. Kết luận
Vậy là chúng ta đã lần lượt tìm hiểu về 3 cách tổ chức dữ liệu đồ thị: Danh sách cạnh, Ma trận kề, Danh sách kề. Mỗi cách đều có ưu và nhược điểm riêng, phù hợp với từng loại thuật toán. Nhưng thuật toán hay dùng nhất chính là Danh sách kề vì tính linh hoạt của nó (vì dùng vector).
Bài viết sau: Đồ thị (Graph) Phần 3: DFS – Thuật toán tìm kiếm theo chiều sâu chúng ta sẽ tìm hiểu về hai thuật toán duyệt đồ thị cơ bản nhất: Thuật toán tìm kiếm theo chiều sâu nhé!.









