
1. Mở đầu
Binary Search – Tìm kiếm nhị phân (hay còn được gọi là Chặt nhị phân) là một trong những thuật toán được sử dụng phổ biến nhất trong lập trình thi đấu bởi tính đa dụng của nó. Chúng được sử dụng để xác định vị trí chính xác của một giá trị nào đó ở trong mảng đã được sắp xếp sẵn với độ phức tạp thời gian thấp. Tư tưởng của thuật toán này như sau:
- So sánh giá trị cần tìm với giá trị đứng giữa của mảng.
- Nếu hai giá trị khác nhau, phần nửa của mảng chắc chắn không chứa giá trị đó sẽ bị bỏ qua và chỉ tìm kiếm trong nửa còn lại.
- Tiếp tục so sánh giá trị cần tìm với giá trị đứng giữa của khoảng cần tìm kiếm, và chỉ lấy một nửa của khoảng đang xét chắc chắn chứa giá trị đó để tìm kiếm tiếp. Lặp lại bước này đến khi tìm thấy giá trị cần tìm.
Ta có ví dụ nhỏ như sau:
Cho mảng (a) được sắp xếp sẵn theo thứ tự từ nhỏ đến lớn gồm (n) phần tử. Cho giá trị (x), tìm vị trí của (x) trong mảng (a).
Input:
- Dòng đầu tiên ghi (n) với (n) là số phần tử của mảng (a) ((n ≤ 10^{5}), (a_{i} ≤ 10^{9})).
- Dòng tiếp theo ghi (n) số nguyên dương theo thứ tự từ bé đến lớn là lần lượt các giá trị từ (a_{1}, a_{2}, …,a_{n}).
- Dòng cuối cùng ghi số nguyên (x).
Output:
- Một dòng duy nhất ghi vị trí của (x) trong mảng (a). Nếu có nhiều phương án, in ra một phương án bất kỳ. Nếu (x) không tồn tại trong mảng (a), in ra (-1).
Sample Input:
6 1 3 5 7 9 11 3
Sample Output:
2
Phân tích bài toán:
- Đây chính là bài toán cơ bản nhất liên quan đến tìm kiếm nhị phân. Dựa vào tư tưởng đã được nhắc ở trên, ta có mã giả cho bài toán này như sau:
ans = -1, l = 1, r = n
trong khi l <= r
mid = (l + r)/2
// vị trí đứng giữa của khoảng đang xét
nếu a[mid] < x
// nếu vị trí đứng giữa của mảng nhỏ hơn x
// => toàn bộ giá trị từ a[1] đến a[mid] đều nhỏ hơn x
// => không cần tìm kiếm khoảng từ a[1] đến a[x] nữa
l = mid + 1
nếu a[mid] > x
// nếu vị trí đứng giữa của mảng nhỏ hơn x
// => toàn bộ giá trị từ a[mid] đến a[n] đều lớn hơn x
// => không cần tìm kiếm khoảng từ a[mid] đến a[n] nữa
r = mid - 1
nếu a[mid] = x
// nếu vị trí đứng giữa của mảng đúng bằng x
// => đó chính là vị trí cần tìm
ans = mid
break;
nếu ans = -1 tức là trong mảng không có giá trị cần tìm
nếu ans khác -1 thì ans chính là vị trí của giá trị cần tìm
Quá trình xử lý của thuật toán trên được hình dung như sau:
- Có (l = 1), (r = 6). Khi đó, (mid = 3).
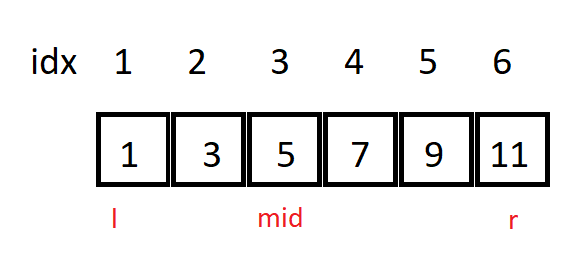

- So sánh (a_{mid}) với (x), nhận thấy (a_{mid}) (>) (x), ta gán lại (r = mid – 1) (do khoảng từ (a_{mid}) đến (a_{n}) chắc chắn không chứa (x) nên ta không tìm kiếm khoảng đó nữa).
- Có (l = 1), (r = 3). Khi đó, (mid = 2).
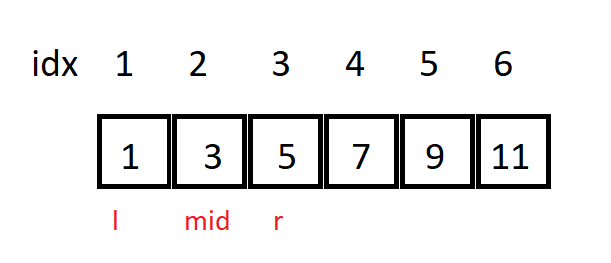

- So sánh (a_{mid}) với (x). Do (a_{mid}) đúng bằng (x) nên (mid) chính là vị trí cần tìm của giá trị (x).
Kết luận: Dễ thấy, thời gian chạy của thuật toán này tuân theo hàm logarit (cụ thể hơn, do bản chất của (log_{2}n) chính là số lần n chia cho 2 đến khi bằng 1) nên độ phức tạp thời gian trong trường hợp xấu nhất của thuật toán này sẽ là (O(log(n))).
Code mẫu:
#include<bits/stdc++.h> using namespace std; const int N = 1e5 + 2; int a[N], n, x; signed main() { ios_base::sync_with_stdio(false); cin.tie(nullptr); cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; cin >> x; int l = 1, r = n, ans = -1; while (l <= r) { int mid = (l + r)/2; if (a[mid] == x) { ans = mid; break; } else if (a[mid] < x) { l = mid + 1; } else { r = mid - 1; } } cout << ans; return 0; }
2. Bài toán 1
Cho mảng (a), các phần tử được đánh số (a_{1}, a_{2}, … , a_{n}). Cho (Q) truy vấn, mỗi truy vấn gồm 2 giá trị (l), (r). Nhiệm vụ của bạn là đếm số phần tử thuộc ([l, r]) của từng truy vấn đó.
Input:
- Dòng đầu tiên ghi số (n), (Q) ((n ≤ 10^{5}), (Q ≤ 10^{5})).
- Dòng tiếp theo ghi (n) số nguyên dương lần lượt là các giá trị (a_{1}, a_{2}…, a_{n}).
- (Q) dòng tiếp theo, mỗi dòng gồm 2 số nguyên dương (l), (r) ((l, r ≤ 10^{9})).
Output:
- In ra (Q) dòng, mỗi dòng là câu trả lời cho từng truy vấn.
Sample Input:
5 2 1 3 5 6 7 1 3 2 7
Sample Output:
2 4
Phân tích bài toán:
- Thông thường khi đọc đề bài này, ta sẽ có xu hướng nghĩ tới việc tìm kiếm vét cạn: duyệt hết tất cả phần tử trong đoạn ([l, r]) và kiểm tra xem phần tử đó tồn tại bao nhiêu lần trong mảng (a). Thế nhưng, độ phức tạp của thuật toán này trong trường hợp xấu nhất có thể lên tới (O(n^{2})) – một con số không thể chấp nhận được. Chính vì vậy, ta buộc phải tìm cách tối ưu hóa thuật toán trên.
- Do thứ tự của mảng không ảnh hưởng tới câu trả lời của truy vấn, ta hoàn toàn có thể sort mảng lại và sử dụng tìm kiếm nhị phân để:
- Tìm kiếm vị trí của phần tử đầu tiên có giá trị lớn hơn hoặc bằng (l). Gọi vị trí tìm được là (x).
- Tìm kiếm vị trí của phần tử đầu tiên có giá trị lớn hơn hẳn (r). Gọi vị trí tìm được là (y).
- Đáp số của bài toán này chính là: (y – x).
Để tìm kiếm vị trí của phần tử đầu tiên có giá trị lớn hơn hoặc bằng giá trị (x) cho trước, ta sẽ sử dụng hàm (lb) để giải quyết. Hàm (lb) như sau:
int lb(int x) { int l = 1, r = n, ans = 0; while (l <= r) { int mid = (l + r)/2; if (a[mid] >= x) { ans = mid; r = mid - 1; // đoạn [mid + 1, r] chắc chắn không thể là // phần tử đầu tiên lớn hơn hoặc bằng x // nhưng mid thì có thể nên ta gán ans = mid } else { l = mid + 1; // đoạn [l, mid] chắc chắn không chứa phần tử // đầu tiên lớn hơn hoặc bằng x nên ta có thể bỏ } } return ans; }
Để tìm kiếm vị trí của phần tử đầu tiên có giá trị lớn hơn hẳn (y) cho trước, ta sẽ sử dụng hàm (ub) để giải quyết. Hàm (ub) như sau:
int ub(int x) { int l = 1, r = n, ans = n + 1; while (l <= r) { int mid = (l + r)/2; if (a[mid] > x) { ans = mid; r = mid - 1; // đoạn [mid + 1, r] chắc chắn không thể là // phần tử đầu tiên lớn hơn hẳn x // nhưng mid thì có thể nên ta gán ans = mid } else { l = mid + 1; // đoạn [l, mid] chắc chắn không chứa phần tử // đầu tiên lớn hơn hẳn x nên ta có thể bỏ } } return ans; }
Code mẫu:
#include<bits/stdc++.h> using namespace std; const int N = 1e5 + 2; int a[N], n, q; int lb(int x) { int l = 1, r = n, ans = n + 1; while (l <= r) { int mid = (l + r)/2; if (a[mid] >= x) { ans = mid; r = mid - 1; } else { l = mid + 1; } } return ans; } int ub(int x) { int l = 1, r = n, ans = n + 1; while (l <= r) { int mid = (l + r)/2; if (a[mid] > x) { ans = mid; r = mid - 1; } else { l = mid + 1; } } return ans; } signed main() { ios_base::sync_with_stdio(false); cin.tie(nullptr); cin >> n >> q; for (int i = 1; i <= n; i++) cin >> a[i]; sort(a + 1, a + 1 + n); while (q-- > 0) { int l, r; cin >> l >> r; l = lb(l), r = ub(r); cout << r - l << 'n'; } return 0; }
- Bên cạnh việc ta code hai hàm (lb), (ub) như trên, ta còn có thể sử dụng hàm có sẵn trong thư viện chuẩn STL
lower_bound,upper_boundlần lượt là các hàm để tìm vị trí đầu tiên lớn hơn hoặc bằng giá trị (x) và lớn hơn hẳn (x). - Với vector, cú pháp của hàm
lower_bound / upper_boundsẽ có dạng như sau:int pos = lower_bound(a.begin(), a.end(), x) - a.begin()với (a) là tên vector cần tìm kiếm nhị phân và phạm vi tìm kiếm là từa.begin()đếna.end().
- Với mảng tĩnh, cú pháp của hàm
lower_bound / upper_boundsẽ có dạng như sau:int pos = lower_bound(a + 1, a + 1 + n, x) - avới (a) là tên mảng tĩnh và phạm vi tìm kiếm là từ (a_{1}) đến (a_{n})
- Chính vì vậy, bài toán trên còn có cách code khác ngắn gọn hơn:
#include<bits/stdc++.h> using namespace std; const int N = 1e5 + 2; int a[N], n, q; signed main() { ios_base::sync_with_stdio(false); cin.tie(nullptr); cin >> n >> q; for (int i = 1; i <= n; i++) cin >> a[i]; sort(a + 1, a + 1 + n); while (q-- > 0) { int l, r; cin >> l >> r; l = lower_bound(a + 1, a + 1 + n, l) - a; r = upper_bound(a + 1, a + 1 + n, r) - a; cout << r - l << 'n'; } return 0; }
3. Bài toán 2
Một loài vật quý hiếm cần được di chuyển từ địa điểm (A) sang địa điểm (B). Loài này rất nhạy cảm với nhiệt độ nên dễ mắc bệnh. Nếu nhiệt độ chênh lệch giữa 2 địa điểm đi qua liên tiếp càng cao thì nguy cơ mắc bệnh của loài càng cao.
Yêu cầu: Hãy tìm một hành trình từ (A) đến (B) sao cho nguy cơ mắc bệnh của loài là thấp nhất có thể.
Input:
- Dòng đầu là số (n) ((n ≤ 10^{4})) số địa điểm.
- Dòng tiếp theo chứa (n) số nguyên là nhiệt độ từng điểm, mỗi số cách nhau một khoảng trắng.
Cho rằng (A) là điểm đầu tiên và (B) là điểm cuối cùng trong hành trình, nhiệt độ ở (A) luôn nhỏ hơn nhiệt độ ở (B). Hành trình từ (A) đến (B) có thể đi qua một vài hay tất cả các điểm đã cho.
Output
- Ghi ra nhiệt độ chênh lệch lớn nhất giữa 2 điểm đi qua liên tiếp
Sample Input:
8 16 21 22 28 18 2 14 19
Sample Output:
2
Giải thích:
Các điểm đi qua: 16 18 19
Phân tích bài toán:
- Nhận xét: nếu tồn tại đường đi có nguy cơ mắc bệnh là (x), cũng đồng nghĩa với việc tồn tại đường đi có nguy cơ lớn nhất (≤) (x + 1), (x + 2…) Từ đây, ta sẽ suy nghĩ tới việc sử dụng thuật toán tìm kiếm nhị phân để giải quyết bài này.
- Cụ thể hơn, ta sẽ xây dựng hàm (check(x)) để kiểm tra xem liệu với nguy cơ mắc bệnh là (x), có tồn tại phương án đi từ (A) đến (B) hay không. Gọi (dp[i]) tức là tồn tại phương án đi từ (A) đến (i) với nguy cơ mắc bệnh là (x). Ta có: (dp[i] = true) nếu tồn tại (j < i) mà (dp[j] = true) và (a_{i} – x ≤ a_{j} ≤ a_{i} + x). Để kiểm soát được điều này, ta sẽ sử dụng set để kiểm tra xem giá trị nhỏ nhất trong mảng (a) lớn hơn (a_{i} – x) có ≤ (a_{i} + x) hay không. Nếu có, gán (dp[i] = true). Qua đó, (check(x) = true) khi (dp[n] = true).
- Dùng tìm kiếm nhị phân để tìm xem giá trị (x) nhỏ nhất mà (check(x) = true) là bao nhiêu, và đó chính là đáp số của bài này.
Code mẫu:
#include<bits/stdc++.h> using namespace std; #define int long long const int N = 1e4 + 5; int n, a[N], dp[N]; bool check(int x) { memset(dp, 0, sizeof dp); set<int> s; set<int> :: iterator it; s.insert(a[1]); for (int i = 2; i <= n; i++) { it = s.lower_bound(a[i] - x); // tìm giá trị đầu tiên lớn hơn hoặc bằng a[i] - x if (it != s.end() && (*it) <= a[i] + x) { // nếu giá trị đó ≤ a[i] + x // nghĩa là tồn tại a[i] - x ≤ a[j] ≤ a[i] + x dp[i] = 1; } if (dp[i]) { s.insert(a[i]); } } return dp[n]; } signed main() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; int l = 1, r = 1e9, ans = -1; while (l <= r) { int mid = (l + r)/2; if (check(mid)) { ans = mid; r = mid - 1; } else { l = mid + 1; } } cout << ans; return 0; }
4. Bài toán 3
Nguồn bài: Meeting on the Line – Codeforces
Tóm tắt đề: Giả sử có (n) người cùng nằm trên một đường thẳng, người thứ (i) nằm ở tọa độ (x_{i}). Chọn một điểm đến để làm trung tâm, gọi là (x_{0}). Thời gian đi từ người thứ (i) đến điểm trung tâm được quy ước là (|x_{i} – x_{0}|). Bên cạnh đó, người thứ (i) cần (t_{i}) thời gian để chuẩn bị, nên thời gian thực tế người thứ (i) đến điểm trung tâm là (t_{i} + |x_{i} – x_{0}|).
Tìm tọa độ (x_{0}) thể hiện thời gian nhỏ nhất mà tất cả (n) người có thể đến được trung tâm.
Input:
- Dòng đầu tiên ghi số (t) ((1 ≤ t ≤ 10^{3})) tương ứng với (t) test.
- Mỗi test bao gồm 3 dòng:
- Dòng đầu tiên ghi số (n) ((1 ≤ n ≤ 10^{5})) – tức (n) người.
- Dòng thứ 2 ghi (n) số nguyên lần lượt là các giá trị (x_{1}, x_{2},…, x_{n}).
- Dòng thứ 3 ghi (n) số nguyên lần lượt là các giá trị (t_{1}, t_{2},… t_{n})
Output:
- In ra số duy nhất là số thực (x_{0}) tìm được, làm tròn đến 6 chữ số sau dấu phẩy.
Phân tích bài toán:
- Giống như bài toán 2, ta có nhận xét như sau: nếu tồn tại cách chọn (x_{0}) mà thời gian tất cả (n) người tới là (x), cũng đồng nghĩa với việc tồn tại cách chọn (x_{0}) mà thời gian tất cả (n) người trên đi tới với thời gian tối đa (> x).
- Xây dựng hàm (check(x)) để kiểm tra xem với thời gian là (x), liệu tất cả (n) người có thể đến được với thời gian ≤ (x) hay không. Để làm được việc này, ta có nhận xét như sau: với mỗi người thứ (i), hãy tìm một đoạn vị trí mà họ có thể đi được trong thời gian là (x). Nếu tồn tại (x) thỏa mãn, tức là (x ≥ t_{i}) thì đoạn vị trí đó sẽ là: ([x_{i} – (x – t_{i}),) (x_{i} + (x – t_{i})]). Vậy, để tồn tại điểm (x_{0}) thỏa mãn, đoạn vị trí nhỏ nhất nằm ở bên phải lớn hơn hoặc bằng đoạn vị trí lớn nhất nằm ở bên trái. Nói cách khác, giả sử mỗi người sẽ có khoảng vị trí đến được trong thời gian (x), nếu giao của tất cả các đoạn đấy khác rỗng thì hàm (check(x)) trả về (true).
Code mẫu:
#include<bits/stdc++.h> using namespace std; #define int long long #define double long double const int N = 1e5 + 2; int n, a[N], t[N]; int limit_min, limit_max; bool check(int x) { limit_max = -1e9, limit_min = 1e9; for (int i = 1; i <= n; i++) { limit_max = max(limit_max, a[i] - (x - t[i])); limit_min = min(limit_min, a[i] + (x - t[i])); } return (limit_max <= limit_min); } signed main() { ios_base::sync_with_stdio(false); cin.tie(nullptr); int tt; cin >> tt; while (tt-- > 0) { cin >> n; for (int i = 1; i <= n; i++) { cin >> a[i]; a[i] *= 2; } for (int i = 1; i <= n; i++) { cin >> t[i]; t[i] *= 2; } int l = *max_element(t + 1, t + 1 + n) - 1, r = 1e9; int ans = -1; while (r - l > 1) { int mid = (l + r)/2; if (check(mid)) { ans = mid; r = mid; } else { l = mid; } } limit_max = -1e9, limit_min = 1e9; for (int i = 1; i <= n; i++) { limit_max = max(limit_max, a[i] - (r - t[i])); limit_min = min(limit_min, a[i] + (r - t[i])); } cout << setprecision(6) << fixed << limit_max/2.0; cout << 'n'; } return 0; }
5. Khi nào sử dụng Binary Search?
- Ứng dụng của tìm kiếm nhị phân vô cùng nhiều do tính đa dụng của nó. Từ những bài toán cơ bản như việc tìm kiếm một phần tử nhất định cho trước trong mảng đã sắp xếp, đến những bài phải kết hợp những thuật toán nâng cao hơn như Segment Tree, Binary Indexed Tree, Quy hoạch động, HLD, DFS/BFS,… Chính vì vậy, đây là một trong những thuật toán cần phải nắm chắc.
- Dấu hiệu nhận biết cần sử dụng Binary Search đó là khi ta cần sử dụng một công cụ để tìm kiếm nhanh con số trong một mảng/tập số thỏa mãn yêu cầu.
6. Luyện tập
Đây là một số bài tập luyện tập trong sách Competitive Programming Basic của Code Dream, đăng ký mua ngay để được luyện tập nhiều dạng bài về thuật toán khác, chấm bài online tại http://oj.codedream.edu.vn
ÁP DỤNG GIẢI BÀI TOÁN LINECUT
Phân tích bài toán:
- Do có thể có phần còn thừa, ta đưa ra nhận xét như sau: Nếu (x) tồn tại cách cắt làm (k) phần, cũng đồng nghĩa với việc chúng tồn tại cách cắt làm (k – 1), (k – 2…) phần.
- Xây dựng hàm (check(x)) để kiểm tra xem với (x), liệu tồn tại cách cắt mà có được (≥ k) phần dây bằng nhau hay không.
Code mẫu:
#include<bits/stdc++.h> using namespace std; #define int long long const int N = 3e4 + 5; int n, k, l[N]; bool check(int x) { int cnt = 0; for (int i = 1; i <= n; i++) { cnt += l[i]/x; } return cnt >= k; } signed main() { cin >> n >> k; for (int i = 1; i <= n; i++) { cin >> l[i]; } int l = 1, r = 1e6 + 5, ans = -1; while (l <= r) { int mid = (l + r)/2; if (check(mid)) { ans = mid; l = mid + 1; } else { r = mid - 1; } } cout << ans; return 0; }









