
Mở đầu
Bài viết này giới thiệu về cây duyệt chiều sâu (Depth First Search Tree – DFS Tree). Đây là một cấu trúc dữ liệu quan trọng, phát sinh từ kỹ thuật duyệt đồ thị ưu tiên chiều sâu (DFS), và là nền tảng để giải quyết các bài toán như tìm điểm khớp, cạnh cầu, và các thành phần liên thông mạnh.
Trước hết, các bạn có thể đọc về thuật toán DFS tại đây nếu chưa làm quen.
Cây duyệt chiều sâu DFS (cây DFS)
-
- Trong quá trình thực hiện DFS, với mỗi đỉnh (u) (ngoại trừ đỉnh gốc của lượt duyệt), ta xác định được đỉnh (par[u]) là đỉnh mà từ đó lời gọi đệ quy DFS đã đến thăm (u). Tập hợp các cạnh có dạng ((par[u], u)) tạo thành một cây, được gọi là cây DFS.
- Các cạnh ((par[u], u)) hình thành nên cây DFS thường được gọi là các cạnh cây (tree edges) hoặc cạnh nét liền.
- Những cạnh còn lại của đồ thị gốc, không thuộc cây DFS, được gọi là cạnh không thuộc cây hoặc cạnh nét đứt.
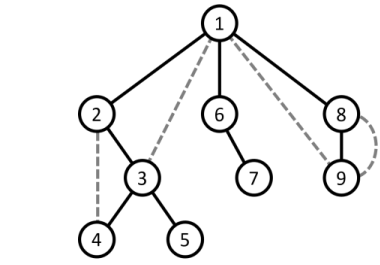
- Đối với đồ thị có hướng, khi xét các cung (cạnh có hướng) dựa trên việc chúng có được duyệt trong quá trình xây dựng cây DFS hay không, ta có thể phân loại chúng thành 4 loại sau:
-
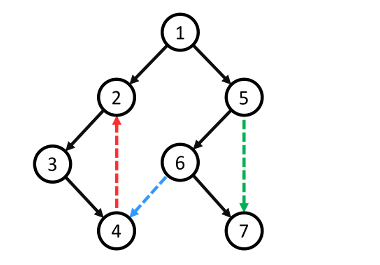
- Cung cây (Tree edge): Là các cung ((u, v)) thuộc cây DFS, với (u) là cha của (v) trong cây. Chúng biểu diễn quá trình khám phá đỉnh mới khi DFS đi từ (u) sang (v). (Ví dụ: cạnh ((u, v)) thuộc cây DFS mà (u) được thăm trước (v), hay (u) là cha của (v), thì cung (u rightarrow v) là cung cây). Các cung cây thường được minh họa bằng màu đen trong hình dưới đây.
- Cung xuôi (Forward edge): Là các cung (u rightarrow v) không thuộc cây DFS, trong đó (u) là tổ tiên của (v) trong cây DFS. Chúng nối một đỉnh tới một hậu duệ không phải con trực tiếp của nó. Trong hình minh họa, chúng có màu xanh lá.
- Cung ngược (Back edge): Là các cung (v rightarrow u) không thuộc cây DFS, trong đó (u) là tổ tiên của (v) trong cây DFS (ngược lại so với cung xuôi). Chúng nối một đỉnh tới một tổ tiên của nó. Trong hình minh họa, chúng có màu đỏ.
- Cung chéo (Cross edge): Là các cung (u rightarrow v) không thuộc cây DFS, mà (u) và (v) không có quan hệ tổ tiên – hậu duệ trong cây DFS (chúng thuộc các nhánh khác nhau hoặc các cây khác nhau trong rừng DFS). Trong hình minh họa, chúng có màu xanh dương.
-
- Đối với đồ thị vô hướng:
- Không tồn tại cung chéo: Lý do là khi DFS thăm đỉnh (u), nó sẽ duyệt qua tất cả các đỉnh (v) kề với (u) mà chưa được thăm. Nếu tồn tại cạnh ((u, v)) mà (u) và (v) không có quan hệ tổ tiên – hậu duệ, thì một trong hai đỉnh (ví dụ (u)) phải được thăm trước. Khi DFS ở (u), nếu (v) chưa thăm, ((u, v)) sẽ trở thành cạnh cây. Nếu (v) đã thăm, ((u, v)) sẽ là cạnh ngược (vì (v) phải là tổ tiên của (u), nếu không (v) đã là con của (u) hoặc thuộc nhánh khác – trường hợp sau không xảy ra như đã giải thích). Do đó, không thể có cạnh chéo nối hai nhánh khác nhau của cùng một cây DFS.
- Do cạnh trong đồ thị vô hướng không có chiều xác định, khái niệm cung xuôi và cung ngược được điều chỉnh lại đơn giản hơn:
- Cạnh cây (Tree edge): Là các cạnh thuộc cây DFS (tương ứng với “cạnh nét liền”). Về mặt kỹ thuật, chúng tương đương với cung cây trong đồ thị có hướng.
- Cạnh ngược (Back edge): Là các cạnh không thuộc cây DFS (tương ứng với “cạnh nét đứt”). Chúng luôn nối một đỉnh tới một tổ tiên của nó trong cây DFS (không bao gồm cha trực tiếp).
- Như vậy, trong đồ thị vô hướng, khi xét dựa trên cây DFS, ta chỉ cần phân biệt hai loại cạnh: cạnh cây và cạnh ngược.
Một số mảng quan trọng trong cây DFS
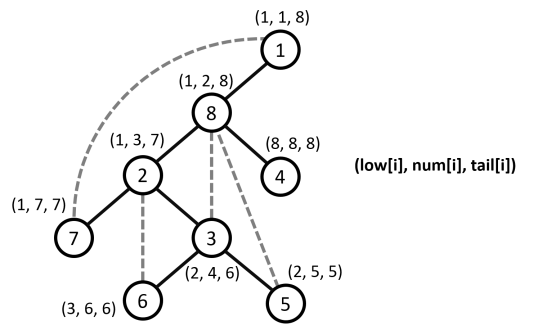
- Mảng (num): Lưu thời điểm bắt đầu thăm (discovery time) của mỗi đỉnh trong quá trình DFS. (num[u]) là một số nguyên, thường là thứ tự mà đỉnh (u) được DFS bắt đầu khám phá (ví dụ, dùng một biến đếm tăng dần).
- Mảng (low): Với mỗi đỉnh (u), (low[u]) là giá trị (num) nhỏ nhất của một đỉnh (v) có thể tới được từ (u) bằng cách đi theo các cạnh cây (xuống dưới) trong cây con gốc (u), và sau đó có thể đi ngược lên qua tối đa một cạnh ngược. Nói cách khác, (low[u]) là chỉ số thăm (num) sớm nhất của một đỉnh (v) sao cho (v) có thể đạt được từ cây con gốc (u) thông qua một đường đi chứa các cạnh cây trong cây con và kết thúc bằng nhiều nhất một cạnh ngược.
- Mảng (tail): Lưu thời điểm kết thúc thăm (finish time) của mỗi đỉnh, tức là thời điểm mà thủ tục DFS của đỉnh đó và tất cả các hậu duệ của nó đã hoàn tất. Đôi khi không cần thiết cho các ứng dụng như tìm khớp/cầu/SCC.
Nhận xét
Một nhận xét quan trọng: Tất cả các đỉnh (v) thuộc cây con gốc (u) trong cây DFS (bao gồm cả (u)) sẽ có (num[u] leq num[v]). Nếu sử dụng mảng (tail), thì (tail[v] leq tail[u]). Khoảng thời gian ([num[u], tail[u]]) (nếu tính (tail)) bao gồm khoảng thời gian xử lý của tất cả các đỉnh trong cây con gốc (u).
Cách tính mảng (low), (num), (tail):
-
- Ý tưởng chính : Mảng (num) và (tail) có thể được tính toán trực tiếp trong quá trình DFS bằng cách sử dụng một biến đếm thời gian toàn cục (ví dụ: (timer)). Mảng (low) được tính dựa trên quan hệ trong cây DFS và các cạnh ngược theo cách đệ quy:
- Khởi tạo: Khi bắt đầu thăm đỉnh (u), gán (num[u] = text{timer++}) và khởi tạo (low[u] = num[u]).
- Cập nhật từ cạnh ngược: Khi xét cạnh ((u, v)), nếu (v) đã được thăm (tức là (num[v]) đã được gán) và (v) không phải là cha trực tiếp của (u) trong cây DFS ((v neq par[u])), thì ((u, v)) là một cạnh ngược (hoặc cạnh xuôi/chéo trong đồ thị có hướng). Cạnh ngược này cho thấy từ (u) có thể “nhảy” tới đỉnh (v) có chỉ số (num) là (num[v]). Ta cập nhật: (low[u] = min(low[u], num[v])).
- Cập nhật từ cạnh cây: Nếu (v) chưa được thăm, thì ((u, v)) là một cạnh cây. Ta gọi đệ quy DFS((v)). Sau khi lời gọi này hoàn tất, giá trị (low[v]) đã được tính toán (cho biết đỉnh có (num) nhỏ nhất mà cây con gốc (v) có thể đạt tới). Vì từ (u) có thể đi xuống (v), và từ (v) có thể tới đỉnh có chỉ số (low[v]), nên ta cập nhật (low[u]) dựa trên (low[v]): (low[u] = min(low[u], low[v])).
- Lưu ý: Giá trị (num[u]) được xác định khi DFS bắt đầu thăm (u). Giá trị (low[u]) (và (tail[u]) nếu có) chỉ được xác định cuối cùng khi DFS kết thúc việc thăm (u) và toàn bộ cây con gốc (u) (tức là sau khi tất cả các lời gọi đệ quy từ (u) đã trở về).
- Cách thực hiện chi tiết:
- Khởi tạo biến đếm thời gian (timer = 0). Bắt đầu duyệt DFS từ một đỉnh gốc tùy ý (hoặc lặp qua tất cả các đỉnh nếu đồ thị không liên thông).
- Khi hàm (DFS(u, parent)) được gọi:
- Gán (num[u] = low[u] = text{timer++}). Đánh dấu (u) đã thăm.
- Lưu (par[u] = parent) (nếu cần).
- Duyệt qua tất cả các đỉnh (v) kề với (u):
- Nếu (v = parent), bỏ qua (tránh đi ngược lại cạnh vừa dùng để tới (u) trong đồ thị vô hướng).
- Nếu (v) đã được thăm ((num[v]) đã được gán): Cạnh ((u, v)) là cạnh ngược/xuôi/chéo. Cập nhật (low[u] = min(low[u], num[v])).
- Nếu (v) chưa được thăm: Cạnh ((u, v)) là cạnh cây. Gọi đệ quy (DFS(v, u)). Sau khi lời gọi này trở về, cập nhật (low[u] = min(low[u], low[v])).
- (Nếu cần tính (tail)) Gán (tail[u] = text{timer++}) tại đây, sau khi đã duyệt hết các con.
- Ý tưởng chính : Mảng (num) và (tail) có thể được tính toán trực tiếp trong quá trình DFS bằng cách sử dụng một biến đếm thời gian toàn cục (ví dụ: (timer)). Mảng (low) được tính dựa trên quan hệ trong cây DFS và các cạnh ngược theo cách đệ quy:
-
- Cài đặt:
int timer = 0; // Thứ tự duyệt DFS void dfs(int u, int parent) { num[u] = low[u] = ++timer; for (int v : g[u]){ if (v == parent) continue; if (!num[v]) { dfs(v, u); low[u] = min(low[u], low[v]); } else low[u] = min(low[u], num[v]); } tail[u] = timer; } - Ví dụ minh họa
- Cài đặt:
Ứng dụng cây DFS trong bài toán tìm khớp, cầu
Định nghĩa
-
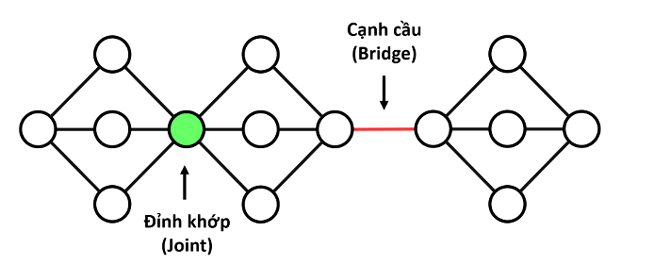
- Đỉnh khớp (Articulation Point): Một đỉnh trong đồ thị vô hướng được gọi là đỉnh khớp nếu việc loại bỏ đỉnh này (cùng với các cạnh kề nó) làm tăng số lượng thành phần liên thông của đồ thị.
- Cạnh cầu (Bridge): Một cạnh trong đồ thị vô hướng được gọi là cạnh cầu nếu việc loại bỏ cạnh này làm tăng số lượng thành phần liên thông của đồ thị.
Bài toán 1
Các bạn có thể nộp thử bài tại đây.
Đề bài: Xét một đơn đồ thị vô hướng. Định nghĩa đỉnh khớp là đỉnh mà việc xóa nó (cùng các cạnh liên thuộc) làm tăng số thành phần liên thông. Tương tự, cạnh cầu là cạnh mà việc xóa nó làm tăng số thành phần liên thông. Yêu cầu: Đếm tất cả các đỉnh khớp và cạnh cầu của đồ thị.
Tìm cạnh cầu
- Chỉ cạnh cây mới có thể là cầu: Một cạnh ngược ((u, v)) không thể là cầu, vì nó cung cấp một đường đi thay thế giữa (u) và (v) thông qua cây DFS (đi từ (v) xuống cây rồi vòng lên (u) qua cạnh ngược). Do đó, ta chỉ cần xét các cạnh cây ((u, v)) (với (u) là cha của (v) trong cây DFS).
- Điều kiện cầu: Xét cạnh cây ((u, v)). Nếu không có bất kỳ cạnh ngược nào xuất phát từ cây con gốc (v) (bao gồm cả (v)) đi lên một đỉnh (w) là (u) hoặc tổ tiên của (u), thì việc xóa cạnh ((u, v)) sẽ tách cây con gốc (v) ra khỏi phần còn lại của đồ thị. Điều này xảy ra khi và chỉ khi đỉnh có (num) nhỏ nhất mà có thể đến được từ cây con gốc (v) (chính là giá trị (low[v])) phải nằm hoàn toàn trong cây con đó, tức là không thể “vươn tới” (u) hoặc cao hơn. Do đó, (num) nhỏ nhất này phải lớn hơn (num[u]).
- Kết luận: Cạnh cây ((u, v)) (với (u) là cha của (v)) là cầu nếu và chỉ nếu (low[v] > num[u]).
Tìm đỉnh khớp
- Ta xét từng đỉnh (u) và xem xét vai trò của nó trong cây DFS. Có hai trường hợp:
- Trường hợp 1: (u) là gốc của cây DFS. Đỉnh (u) là khớp nếu nó có nhiều hơn một con trực tiếp trong cây DFS. Lý do là việc xóa (u) sẽ làm mất kết nối giữa các cây con bắt nguồn từ các con khác nhau của (u) (vì không có cạnh chéo trong đồ thị vô hướng nối trực tiếp giữa các cây con này).
- Trường hợp 2: (u) không phải là gốc của cây DFS. Đỉnh (u) là khớp nếu tồn tại ít nhất một con trực tiếp (v) của (u) trong cây DFS sao cho không có đỉnh nào trong cây con gốc (v) (kể cả (v)) có cạnh ngược nối lên một tổ tiên thực sự của (u) (tức là một đỉnh (w) với (num[w] < num[u])). Điều này có nghĩa là đường đi duy nhất từ cây con gốc (v) lên phần đồ thị phía trên (u) phải đi qua (u). Điều kiện này được thể hiện qua (low[v] geq num[u]). Nếu (low[v] geq num[u]), thì cây con gốc (v) không thể “vòng” lên cao hơn (u) thông qua một cạnh ngược, do đó xóa (u) sẽ tách (v) và cây con của nó ra.
- Kết luận: Đỉnh (u) là đỉnh khớp khi:(1) (u) là gốc của cây DFS và có ít nhất 2 con trực tiếp trong cây DFS.Hoặc:
(2) (u) không phải là gốc của cây DFS và tồn tại ít nhất một con trực tiếp (v) của (u) trong cây DFS sao cho (low[v] geq num[u]).
Cài đặt
#include <iostream>
using namespace std;
const int MAXN = 10010;
int n, m;
bool joint[MAXN];
int timer = 0, bridge = 0;
int low[MAXN], num[MAXN];
vector<int> g[MAXN];
void dfs(int u, int parent) {
int child = 0; // Số lượng con trực tiếp của đỉnh u trong cây DFS
num[u] = low[u] = ++timer;
for (int v : g[u]) {
if (v == parent) continue;
if (!num[v]) {
dfs(v, u);
low[u] = min(low[u], low[v]);
if (low[v] == num[v]) bridge++;
child++;
if (u == parent) { // Nếu u là đỉnh gốc của cây DFS
if (child > 1) joint[u] = true;
}
else if (low[v] >= num[u]) joint[u] = true;
}
else low[u] = min(low[u], num[v]);
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) { int u, v; cin >> u >> v;
g[u].push_back(v);
g[v].push_back(u);
}
for (int i = 1; i <= n; i++)
if (!num[i]) dfs(i, i);
int cntJoint = 0;
for (int i = 1; i <= n; i++) cntJoint += joint[i];
cout << cntJoint << ' ' << bridge;
}
Đánh giá
- Độ phức tạp thời gian của thuật toán tìm khớp và cầu dựa trên DFS và mảng (low), (num) là (O(N+M)), với (N) là số đỉnh và (M) là số cạnh, vì mỗi đỉnh và cạnh được thăm một số lần hằng số.
Ứng dụng cây DFS trong bài toán liệt kê thành phần liên thông mạnh
Định nghĩa
-
- Liên thông mạnh (Strongly Connected): Một đồ thị có hướng được gọi là liên thông mạnh nếu với mọi cặp đỉnh (u, v), tồn tại đường đi từ (u) đến (v) và đường đi từ (v) đến (u).
- Thành phần liên thông mạnh (Strongly Connected Component – SCC): Một tập con tối đại các đỉnh của đồ thị có hướng sao cho với mọi cặp đỉnh (u, v) trong tập con, cả (u) và (v) đều có thể đến được lẫn nhau. “Tối đại” nghĩa là không thể thêm bất kỳ đỉnh nào khác vào tập hợp mà vẫn duy trì tính liên thông mạnh. Nếu mỗi SCC được co lại thành một đỉnh duy nhất, đồ thị thu được sẽ là một Đồ thị có hướng không có chu trình (Directed Acyclic Graph – DAG).
- Các thuật toán phổ biến để tìm SCC bao gồm thuật toán Kosaraju, thuật toán Tarjan, và thuật toán Gabow. Tất cả đều có độ phức tạp thời gian tuyến tính (O(N+M)). Thuật toán Tarjan thường được ưa chuộng vì chỉ yêu cầu một lượt DFS, trong khi Kosaraju cần hai lượt.
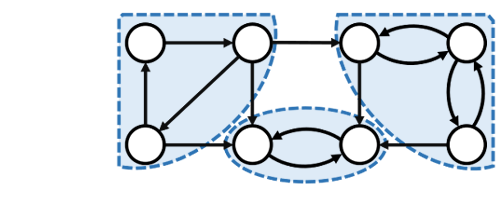
Một số định lý quan trọng
- Định lý 1: Nếu hai đỉnh (a) và (b) cùng thuộc một thành phần liên thông mạnh (C), thì mọi đỉnh nằm trên bất kỳ đường đi nào từ (a) đến (b) hoặc từ (b) đến (a) cũng đều thuộc (C).
Chứng minh: Giả sử (v) nằm trên đường đi từ (a) đến (b). Ta có đường đi (a rightarrow v) và (v rightarrow b). Vì (a, b in C), tồn tại đường đi (b rightarrow a). Do đó, ta có (v rightarrow b rightarrow a), suy ra (v) đến được (a). Ta cũng có (a rightarrow v). Vậy (a) và (v) liên thông mạnh, nên (v in C). Lập luận tương tự cho đỉnh trên đường đi từ (b) đến (a). - Định lý 2: Với mỗi thành phần liên thông mạnh (C), tồn tại duy nhất một đỉnh (r in C) (gọi là chốt hay gốc của (C)) sao cho (r) là đỉnh được thăm đầu tiên trong số các đỉnh thuộc (C) bởi thuật toán DFS. Hơn nữa, tất cả các đỉnh khác của (C) đều là hậu duệ của (r) trong cây/rừng DFS.
Chứng minh: Gọi (r) là đỉnh trong (C) có (num[r]) nhỏ nhất. Xét một đỉnh (v in C), (v neq r). Vì (C) liên thông mạnh, có đường đi từ (r) đến (v). Tất cả các đỉnh trên đường đi này đều thuộc (C) (theo Định lý 1) và do đó có (num) không nhỏ hơn (num[r]). Khi DFS bắt đầu từ (r), tất cả các đỉnh khác trong (C) đều chưa được thăm. Vì có đường đi từ (r) đến mọi (v in C), thuật toán DFS sẽ thăm tất cả các đỉnh này như là một phần của cây con gốc (r). Do đó, mọi (v in C) ((v neq r)) là hậu duệ của (r). Tính duy nhất của (r) suy ra từ việc nó có (num) nhỏ nhất. - Định lý 3: Trong đồ thị có hướng, luôn tồn tại ít nhất một thành phần liên thông mạnh (C) sao cho không có cạnh nào đi từ một đỉnh trong (C) tới một đỉnh thuộc một thành phần liên thông mạnh khác (xét trong đồ thị co các SCC lại). Chốt (r) của thành phần (C) như vậy có tính chất: tất cả các đỉnh trong cây con DFS gốc (r) mà chưa được gán vào SCC nào khác chính là các đỉnh của (C).
Chứng minh: Xem xét đồ thị DAG của các SCC. Luôn tồn tại ít nhất một SCC không có cung đi ra SCC khác (một “lá” trong DAG). Gọi SCC đó là (C) và chốt của nó là (r). Mọi đỉnh (v) trong cây con DFS gốc (r) phải thuộc (C). Nếu (v) thuộc SCC khác (C’), thì (C’) phải có cung đến (C) (vì (v) là hậu duệ của (r)), nhưng (C) không có cung đi ra, mâu thuẫn với cấu trúc DAG. Do đó, toàn bộ cây con gốc (r) (mà chưa bị xác định thuộc SCC khác) chính là (C). Thuật toán Tarjan dựa trên việc tìm ra các chốt (r) thỏa mãn điều kiện này.
Bài toán 2
Các bạn có thể nộp thử bài tại đây.
Đề bài: Cho một đồ thị (G) có hướng. Hãy đếm số thành phần liên thông mạnh của (G).
Ta sẽ ứng dụng thuật toán Tarjan để giải quyết bài toán trên.
Thuật toán Tarjan được xây dựng dựa trên các dữ kiện sau:
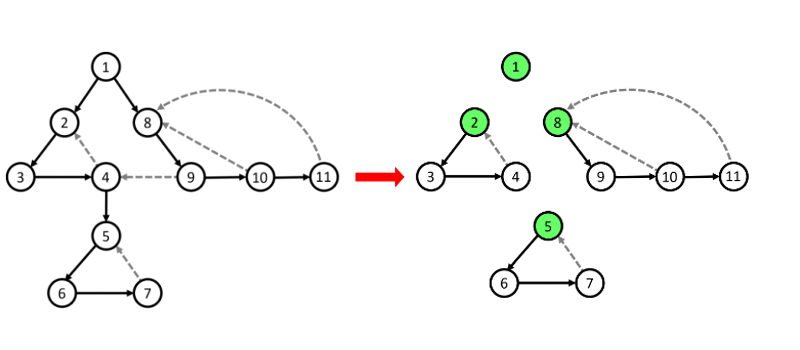
- Tìm kiếm DFS tạo ra cây/rừng DFS.
- Các thành phần liên thông mạnh (SCC) hình thành các cấu trúc liên quan đến cây con của cây DFS. Mỗi SCC có một đỉnh gốc (chốt) duy nhất là đỉnh được thăm đầu tiên trong SCC đó.
- Nếu ta xác định được đỉnh gốc (u) của một SCC, thì tất cả các đỉnh thuộc SCC đó (và chưa được xác định trước đó) hiện đang nằm trên một ngăn xếp (stack) được duy trì bởi thuật toán, từ đỉnh (u) trở lên đỉnh stack.
- Không có cung ngược (back edge) hoặc cung chéo (cross edge) đi từ một SCC này sang một SCC khác mà đã được hoàn thành và loại bỏ khỏi stack trước đó.
Ý tưởng thuật toán Tarjan
- Nhận xét then chốt: Đỉnh (u) là gốc (chốt) của một SCC nếu và chỉ nếu giá trị (low[u]) bằng với (num[u]). Điều này có nghĩa là không có đường đi nào từ (u) hoặc các hậu duệ của nó trong cây DFS (mà vẫn còn trên stack) có thể “vòng lên” tới một đỉnh có (num) nhỏ hơn (num[u]) thông qua một cạnh ngược hoặc chéo.
- Thuật toán sử dụng DFS, mảng (num), mảng (low), và một ngăn xếp (stack) để lưu các đỉnh đang được xem xét.
- Khi duyệt DFS đến đỉnh (u):
- Gán (num[u] = low[u] = text{timer++}).
- Đẩy (u) vào stack. Đánh dấu (u) đang ở trên stack.
- Duyệt qua các đỉnh (v) kề với (u):
- Nếu (v) chưa được thăm: Gọi đệ quy (DFS(v)). Sau đó, cập nhật (low[u] = min(low[u], low[v])).
- Nếu (v) đã được thăm và (v) đang ở trên stack: Cạnh ((u, v)) là cạnh ngược hoặc chéo tới một phần của SCC hiện tại hoặc SCC cha/tổ tiên chưa hoàn thành. Cập nhật (low[u] = min(low[u], num[v])). (Chú ý: dùng (num[v]), không phải (low[v])).
- Sau khi duyệt hết các cạnh kề từ (u) (kết thúc khám phá (u) và cây con của nó): Kiểm tra nếu (low[u] == num[u]).
- Nếu đúng, (u) là gốc của một SCC.
- Tiến hành lấy các đỉnh từ stack ra cho đến khi gặp (u). Tất cả các đỉnh được lấy ra (bao gồm cả (u)) tạo thành một SCC.
- Đánh dấu các đỉnh này là đã thuộc về một SCC và đã bị loại khỏi stack.
- Lặp lại quá trình DFS cho tất cả các đỉnh chưa được thăm để đảm bảo xử lý hết các thành phần liên thông (các cây trong rừng DFS).
Cài đặt
#include <iostream>
using namespace std;
const int MAXN = 100010;
int n, m;
int timer = 0, scc = 0;
int low[MAXN], num[MAXN];
bool deleted[MAXN];
vector<int> g[MAXN];
stack<int> st;
void dfs(int u) {
num[u] = low[u] = ++timer;
st.push(u);
for (int v : g[u]) {
if (deleted[v]) continue;
if (!num[v]){
dfs(v);
low[u] = min(low[u], low[v]);
}
else low[u] = min(low[u], num[v]);
}
if (low[u] == num[u]) {
scc++;
int v;
do {
v = st.top();
st.pop();
deleted[v] = true;
}
while (v != u);
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) { int u, v; cin >> u >> v;
g[u].push_back(v);
}
for (int i = 1; i <= n; i++)
if (!num[i]) dfs(i);
cout << scc;
}
Đánh giá
- Độ phức tạp của thuật toán Tarjan là (O(N+M)) vì mỗi đỉnh và mỗi cạnh chỉ được xử lý một số lần hằng số trong quá trình DFS và các thao tác với stack.









